What is duplicate content?
Duplicate content (DC) is nothing more, than the same content duplicated on different pages of the website.
DC on our website may arise as a result of deliberate action (unconsolidated content strategy), but it often happens that it is strictly technical (e.g. indexing the same resources under multiple URLs by the page engine) or human error.
Clusteric Auditor can help you automatically identify this kind of situation by finding pages that are almost identical, for example, very similar articles.
How do you find duplicate content on the site?
We start with on-site analysis mode.
In our example, we will try to analyze DIY guide on one of the popular construction-related sites.
Let’s provide the address where we want to start crawling the site.
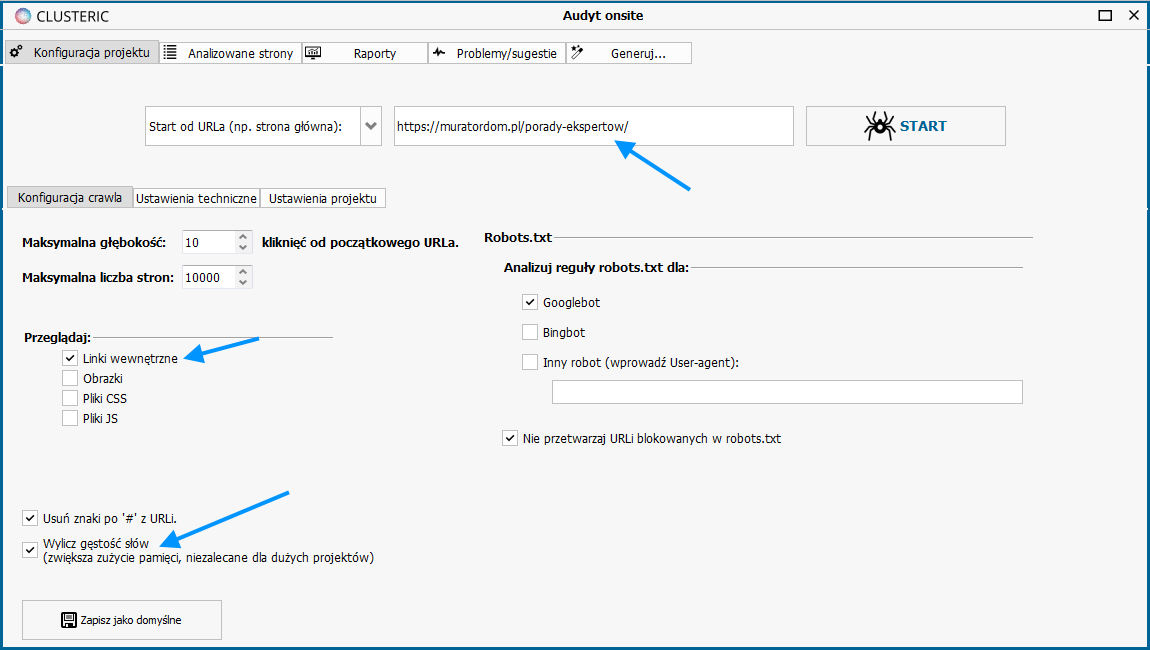
We choose the analysis of internal links (without other resources, we are only interested in texts).
In addition, we necessarily set the density analysis of words in the content of the page – it is the basis for a later duplicate content scan.
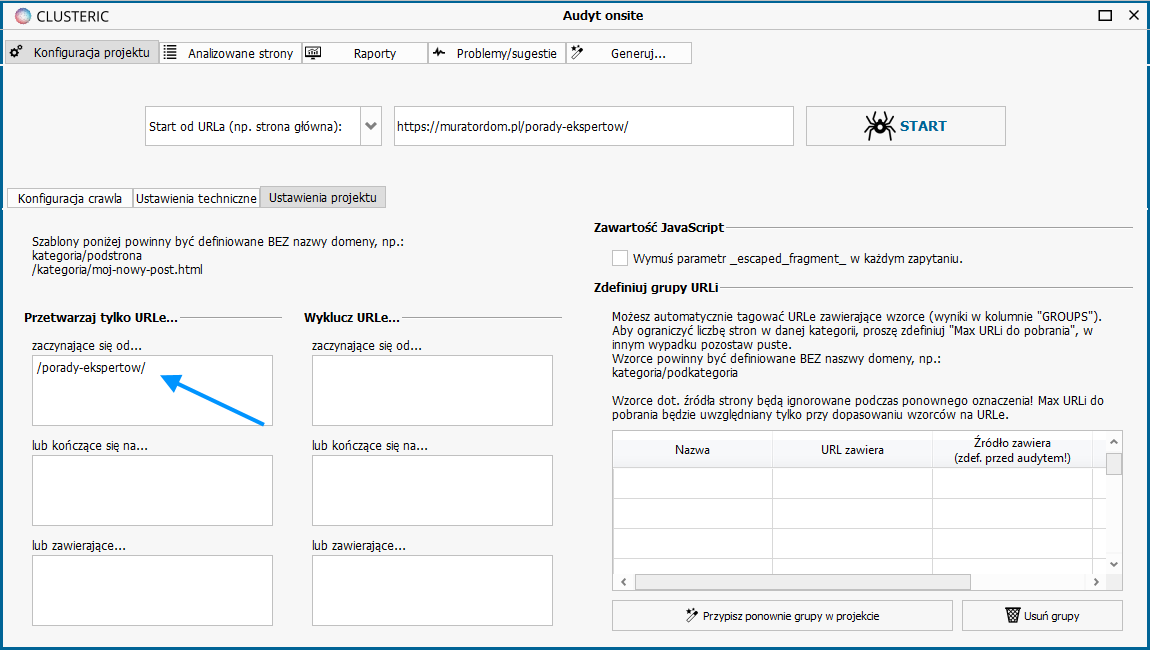
In the next screen we set one more configuration option – in our example we want to analyze the website only in the section devoted to guides.
We run the analysis. When it finishes, we go to the “Generate” and “Similarity scan” tabs.

We’re interested in Google’s point of view, so we’re focusing on indexable resources and without canonical URLs. In addition, you’ll usually want to exclude page text from the analysis that is repeated on many other pages.
These are usually menu elements, constant components of headers or footers, information on privacy policy, cookies, GDPR, etc.
We can also determine what the minimum degree of similarity will cause the texts to appear in the list (scale up to 100 points).
Strong duplicates will usually have over 70 points, but by setting lower values we can also look for articles that are simply related thematically and use the statement for a slightly different purpose (e.g. adding related or internal links, change content strategy or rewrite them).
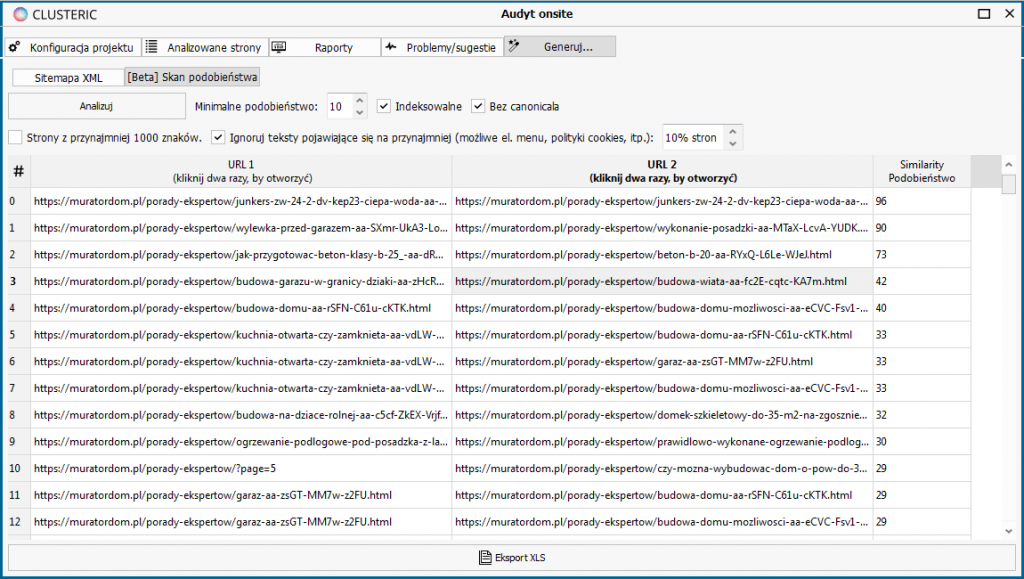
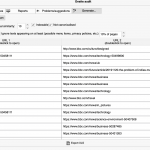
We run the analysis and after a while (depending on the size of the project) we receive:
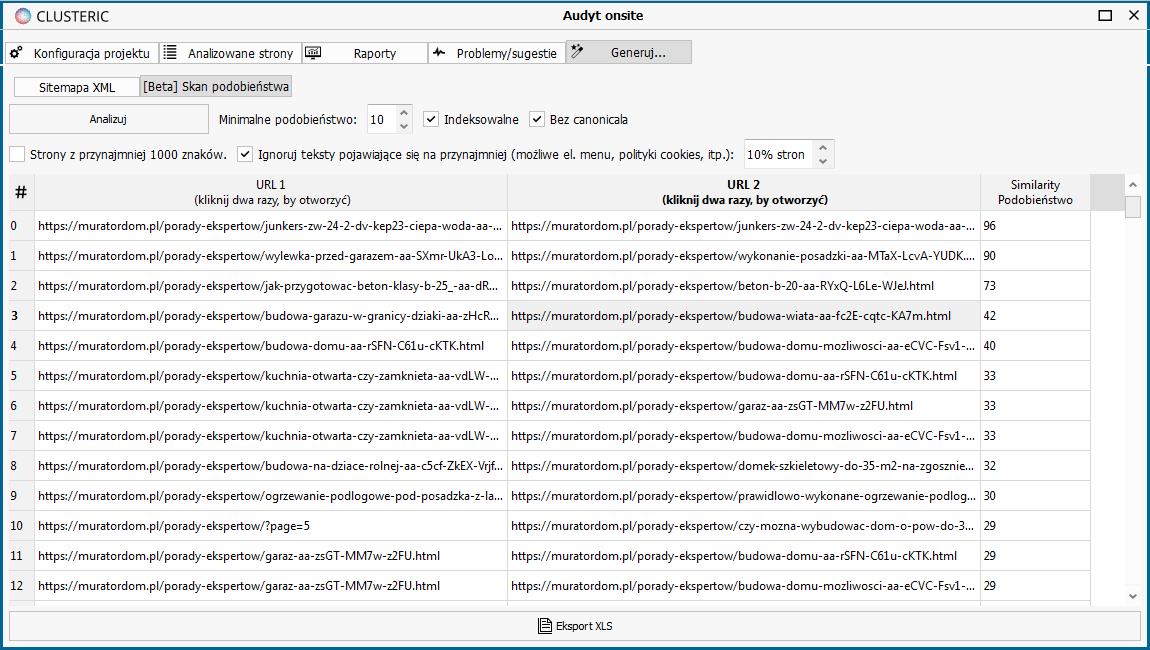
If we look at the results in our example, we will see that the list has two strong duplicates (90 and 96 points), but also texts with a very high degree of coverage with minor changes relative to each other (73 points).

The resulting report can also be exported to XLS.
We strongly advise checking duplicate/similar content on your website to avoid technical problems, cannibalisation and improve content strategy.
The free version provides a full on-site report for 1000 URLs and this option is also limited to 1000 URLs, which is almost like unlimited as you can use filters in the crawl to split analyses.


0 Comments
Leave A Comment