Co to jest duplicate content?
Duplicate content (DC) to nic innego jak ta sama treść powielona na różnych podstronach serwisu.
DC w naszym serwisie może powstać w wyniku świadomego działania ale często zdarza się, że to kwestia stricte techniczna (np. indeksowanie tych samych zasobów pod wieloma adresami URL przez silnik strony) lub błąd ludzki.
Clusteric Auditor może pomóc w automatycznym zidentyfikowaniu tego rodzaju sytuacji znajdując zarówno strony będące niemal stuprocentowymi kopiami jak i np. bardzo podobne artykuły.
Jak znaleźć duplicate content w serwisie?
Rozpoczynamy od trybu analizy on-site.
W naszym przykładzie spróbujemy zrobić analizę tekstów poradnikowych na jednej z popularnych stron o tematyce budowlanej.
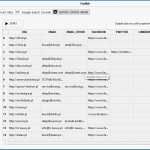
Podajemy adres, od którego chcemy rozpocząć crawl serwisu.
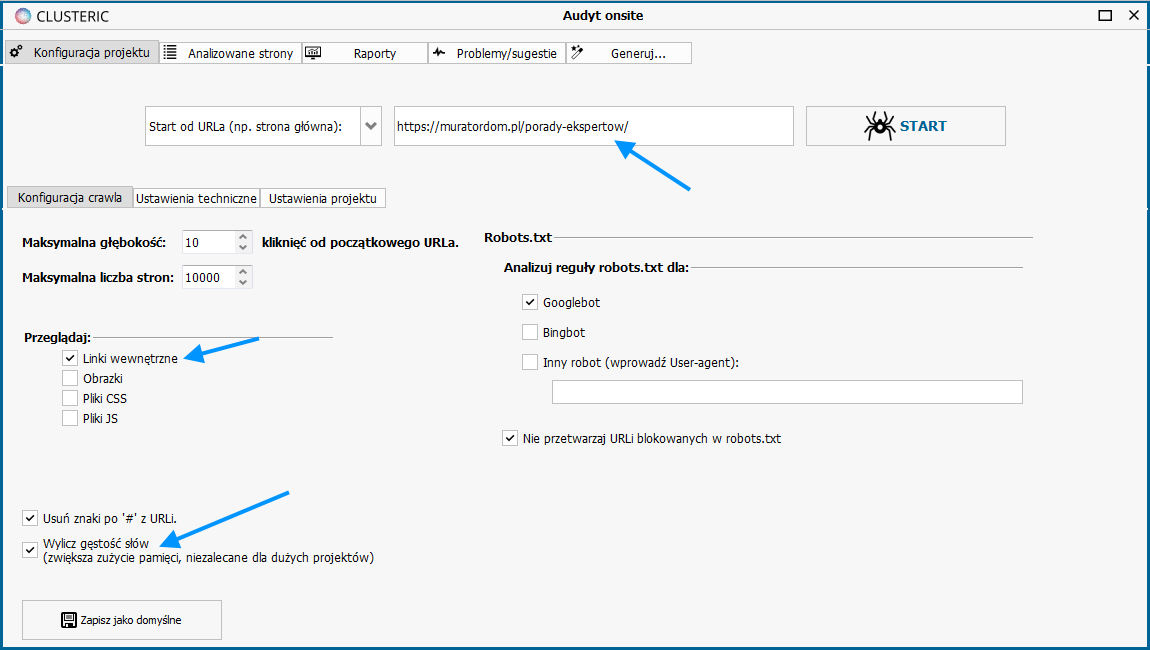
Wybieramy analizę linków wewnętrznych (bez innych zasobów, interesują nas tylko teksty).
Oprócz tego koniecznie ustawiamy analizę gęstości słów w treści strony – jest ona podstawą do późniejszego skanu duplicate content.
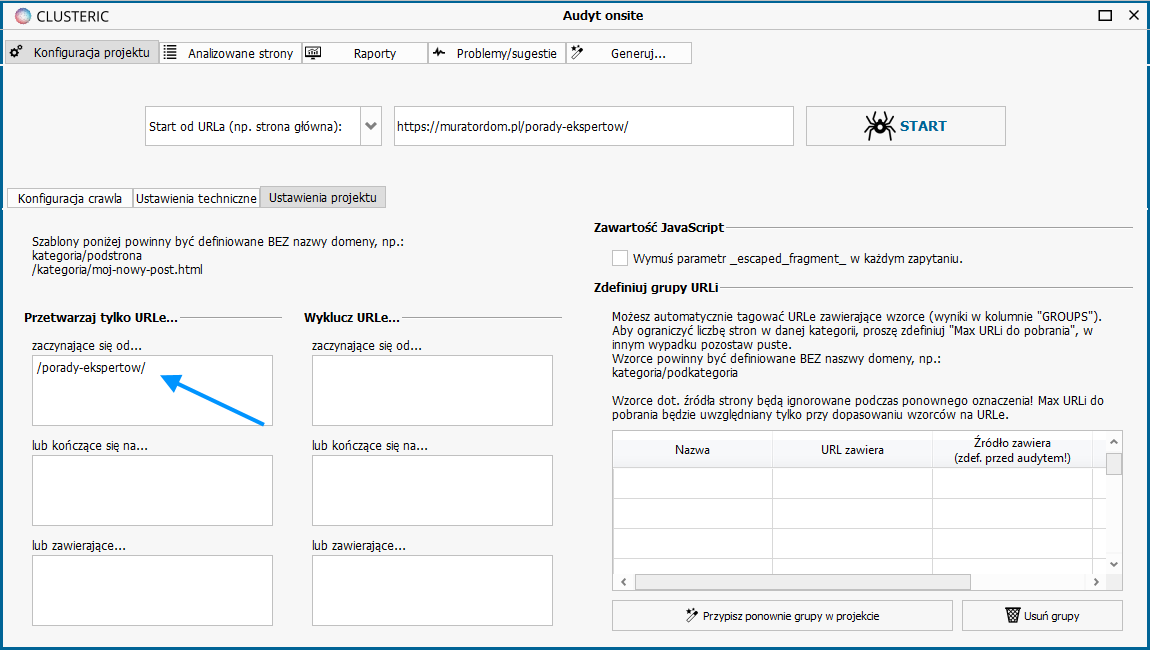
W kolejnym ekranie ustawiamy jeszcze jedną opcję konfiguracyjną – w naszym przykładzie chcemy analizować serwis wyłącznie w części poświęconej poradnikom.
Uruchamiamy analizę. Gdy ta się zakończy, przechodzimy do zakładki “Generuj” i “Skan podobieństwa”.
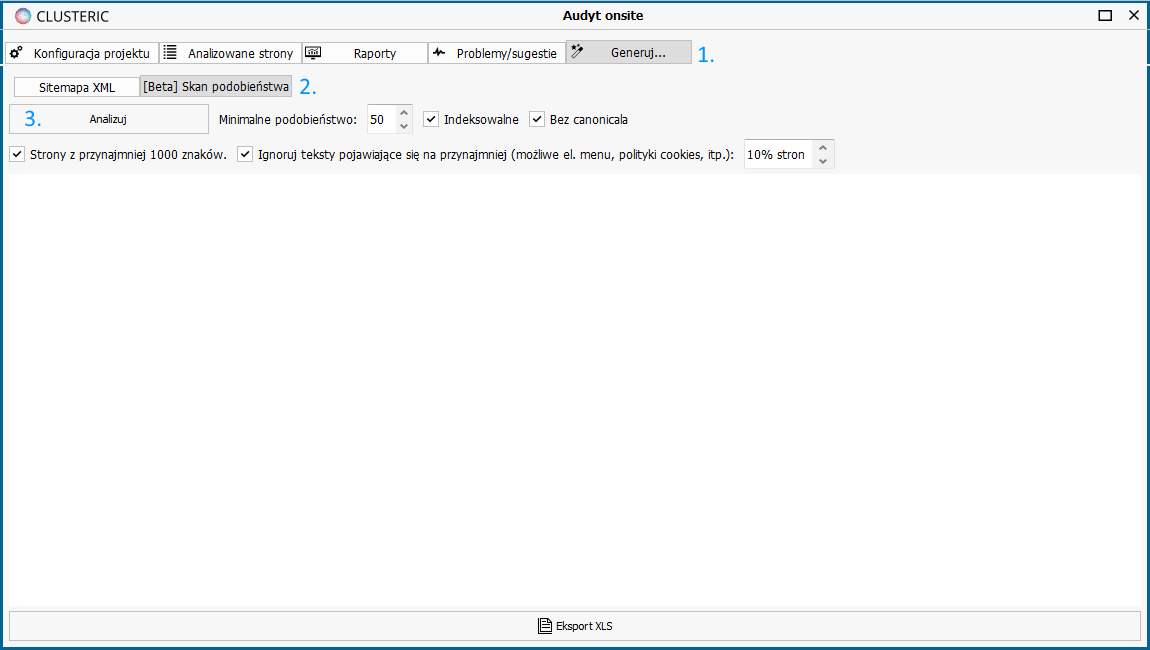
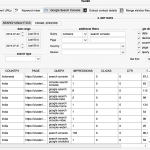
Interesuje nas punkt widzenia Google, więc skupiamy się na zasobach indeksowalnych i bez canonical URL. Oprócz tego, zwykle będziemy chcieli wykluczyć z analizy teksty na stronie, które powtarzają się na wielu innych stronach.
Są to zwykle elementy menu, stałe składowe nagłówków lub footerów, informacje o polityce prywatności, cookies, RODO itd.
Możemy też ustalić, jaki minimalny stopień podobieństwa spowoduje pokazanie się tekstów w zestawieniu (skala do 100 punktów).
Silne duplikaty będą miały zwykle powyżej 70 punktów, ale ustawiając niższe wartości możemy też szukać artykułów, które są po prostu pokrewne tematycznie i wykorzystać zestawienie w nieco innym celu (np. dodanie powiązanych czy linków wewnętrznych).
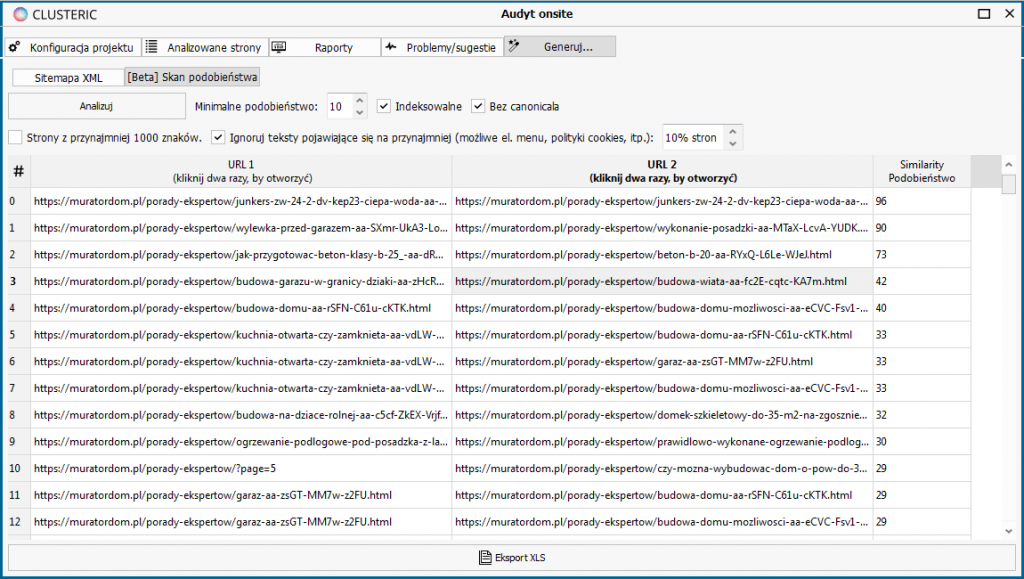
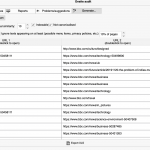
Uruchamiamy analizę i po chwili oczekiwania (czas zależny od wielkości projektu) otrzymujemy:
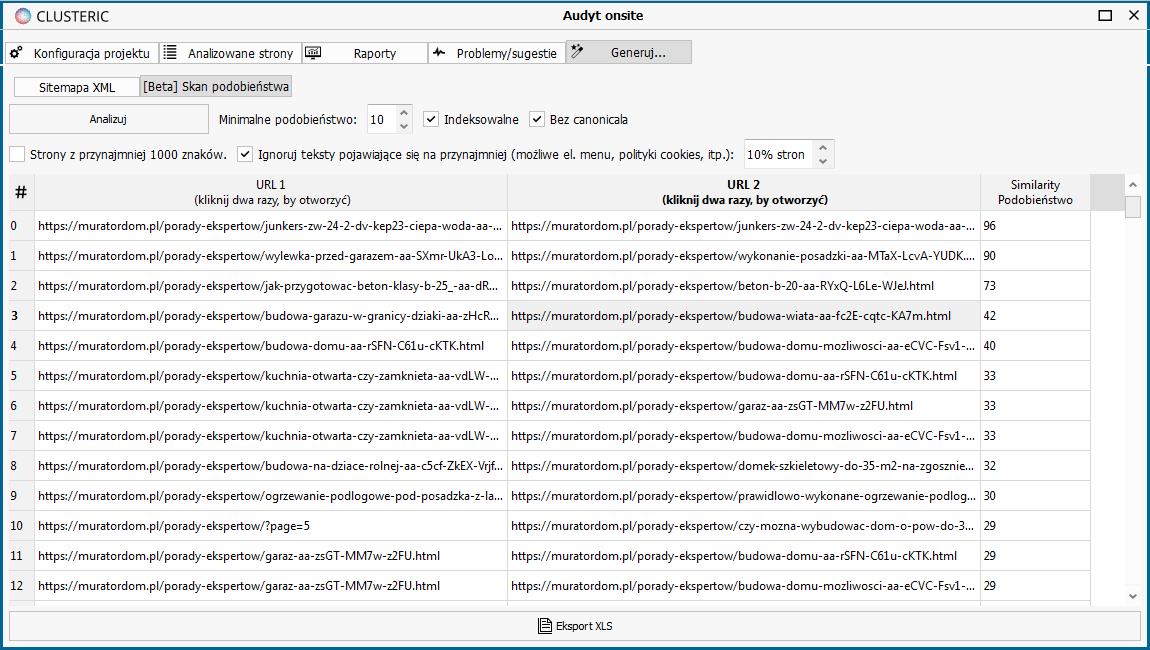
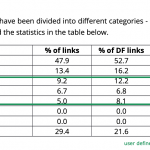
Jeśli przyjrzymy się wynikom w naszym przykładzie, zobaczymy, że na liście są dwa mocne duplikaty (90 i 96 punktów), ale również teksty o bardzo dużym stopniu pokrycia z drobnymi zmianami względem siebie (73 punkty).

Uzyskany raport można też wyeksportować do arkusza XLS.


9 komentarzy
Super opcja, mega wiele upraszcza jeśli chodzi o szukanie duplikacji treści!
Takie było założenie. :) Świetnie, cieszymy się!
Czy to zagadnienie jest też związane z Mixed signals? Gdzie te same anchory kierują do podobnych stron? Nawet jeżeli treść jest napisana ręcznie i unikalna?
Super narzędzie:)) to tak dużych serwisów jak własnie muratordom przydaje się jak najbardziej, bo ręczne wyszukiwanie jest wręcz niemożliwe.. a z doświadczenia wiem ze klienci potrafią zakopać tak głęboko treści że nigdy nie pozbędziemy eis problemu. Ale CLUSTERIC sprawdza się w 100 %:)
Świetne narzędzie, zwłaszcza dla ludzi prowadzących bloga. Dziękuję :)
Jak myślicie - ;'duplicate content' mocno wpływa negatywnie dla SEO strony? A co jak mamy zawarte wypowiedzi specjalistów z informacja o źródle? To także w jakiś sposób duplikat.. Słyszałem także przypadki ale to jakiś czas temu, gdzie pewna strona skopiowała 1 / 1 stronę konkurencji i ta nowa strona na lepiej rankowała i Google uznał ze to ona ma kontent warty uwagi, a stara strona to duplikat...
Bardzo fajna opcja :) Oby więcej takich rozwiązań automatyzujących pracę :)
Bardzo fajna opcja :) Oby więcej takich rozwiązań automatyzujących pracę :) Wgl. Clusteric to dobre narzędzie do analizy konkurencji i modyfikacji strategii w oparciu o wyciągnięte wnioski. Poza duplikacją contentu fajne rozwiązanie do szybkiej analizy profilu linków :)
Kawał dobrej roboty z tymi instrukcjami krok po kroku. Dzięki!
Dodaj komentarz